Mysql学习总结(三)
Mysql学习总结(三)
索引相关
索引类型
- 主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
- 唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
- 普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
- 全文索引:是目前搜索引擎使用的一种关键技术,对文本的内容进行分词、搜索。
- 覆盖索引:查询列要被所建的索引覆盖,不必读取数据行
- 组合索引:多列值组成一个索引,用于组合搜索,效率大于索引合并
索引失效情况
- 查询条件包含or,可能导致索引失效
- 如果字段类型是字符串,where时一定用引号括起来,否则索引失效
- like通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用mysql的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql估计使用全表扫描要比使用索引快,则不使用索引。
聚集索引与非聚集索引
- 一个表中只能拥有一个聚集索引,而非聚集索引一个表可以存在多个。
- 聚集索引,索引中键值的逻辑顺序决定了表中相应行的物理顺序;非聚集索引,索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
- 聚集索引:物理存储按照索引排序;非聚集索引:物理存储不按照索引排序;
两种索引的使用情况表(表总结自https://github.com/whx123/JavaHome)
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
|---|---|---|
| 列经常被分组排序 | 是 | 是 |
| 返回某范围内数据 | 是 | 否 |
| 一个或极少不同值 | 否 | 否 |
| 小数目的不同值 | 是 | 否 |
| 大数目的不同值 | 否 | 是 |
| 频繁更新的列 | 否 | 是 |
| 外键列 | 是 | 是 |
| 主键列 | 是 | 是 |
| 频繁修改索引列 | 否 | 是 |
创建索引原则
- 最左前缀匹配原则
- 频繁作为查询条件的字段才去创建索引
- 频繁更新的字段不适合创建索引
- 索引列不能参与计算,不能有函数操作
- 优先考虑扩展索引,而不是新建索引,避免不必要的索引
- 在order by或者group by子句中,创建索引需要注意顺序
- 区分度低的数据列不适合做索引列(如性别)
- 定义有外键的数据列一定要建立索引。
- 对于定义为text、image数据类型的列不要建立索引。
- 删除不再使用或者很少使用的索引
常见创建索引三种方式
- 在执行CREATE TABLE时创建索引
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`date` datetime DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;- 使用ALTER TABLE命令添加索引
ALTER TABLE table_name ADD INDEX index_name (column);- 使用CREATE INDEX命令创建
CREATE INDEX index_name ON table_name (column);优化SQL
大致可从以下几个方面考虑.
加索引
适量分批量进行
优化sql结构
分库分表
分库分表方案:
- 水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
- 水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
- 垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
- 垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
常用的分库分表中间件:
- sharding-jdbc(当当)
- Mycat
- TDDL(淘宝)
- Oceanus(58同城数据库中间件)
- vitess(谷歌开发的数据库中间件)
- Atlas(Qihoo 360)
分库分表可能遇到的问题:
- 事务问题:需要用分布式事务啦
- 跨节点Join的问题:解决这一问题可以分两次查询实现
- 跨节点的count,order by,group by以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
- 数据迁移,容量规划,扩容等问题
- ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID
- 跨分片的排序分页问题(后台加大pagesize处理?)
读写分离
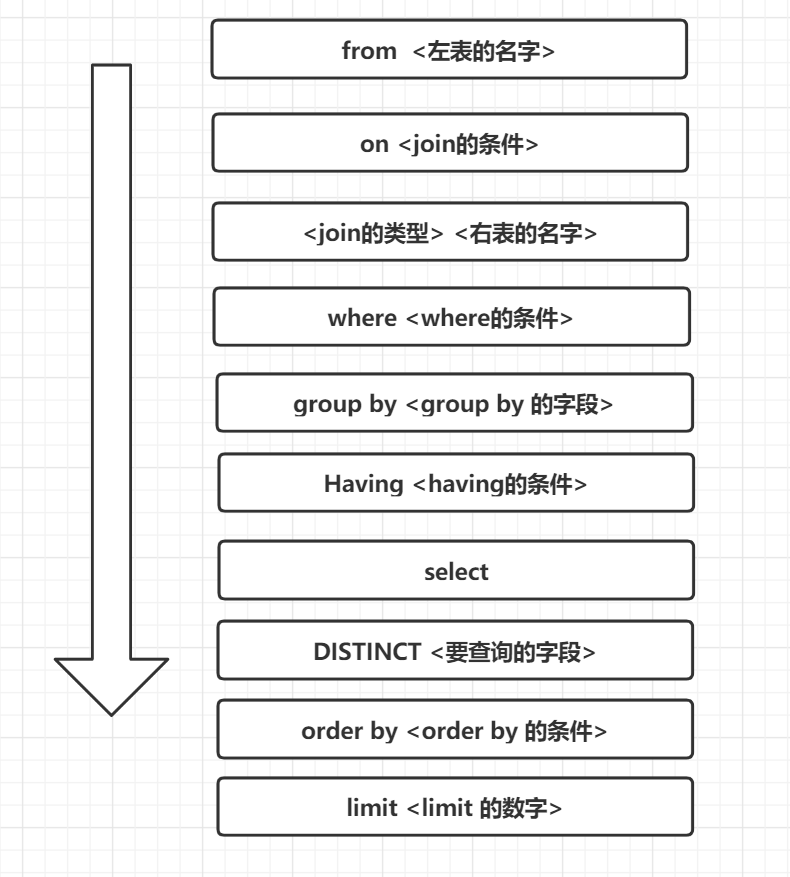
SQL语句的执行顺序
总结
SQL优化的一般步骤分为三步:
- show status 命令了解各种 sql 的执行频率
- 通过慢查询日志定位那些执行效率较低的 sql 语句
- explain 分析低效 sql 的执行计划
存储引擎
InnoDB与MyISAM
- InnoDB支持事务,MyISAM不支持事务
- InnoDB支持外键,MyISAM不支持外键
- InnoDB 支持 MVCC(多版本并发控制),MyISAM 不支持
- select count(*) from table时,MyISAM更快,因为它有一个变量保存了整个表的总行数,可以直接读取,InnoDB就需要全表扫描。
- Innodb不支持全文索引,而MyISAM支持全文索引(5.7以后的InnoDB也支持全文索引)
- InnoDB支持表、行级锁,而MyISAM支持表级锁。
- InnoDB表必须有主键,而MyISAM可以没有主键
- Innodb表需要更多的内存和存储,而MyISAM可被压缩,存储空间较小,。
- Innodb按主键大小有序插入,MyISAM记录插入顺序是,按记录插入顺序保存。
- InnoDB 存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全,与 MyISAM 比 InnoDB 写的效率差一些,并且会占用更多的磁盘空间以保留数据和索引
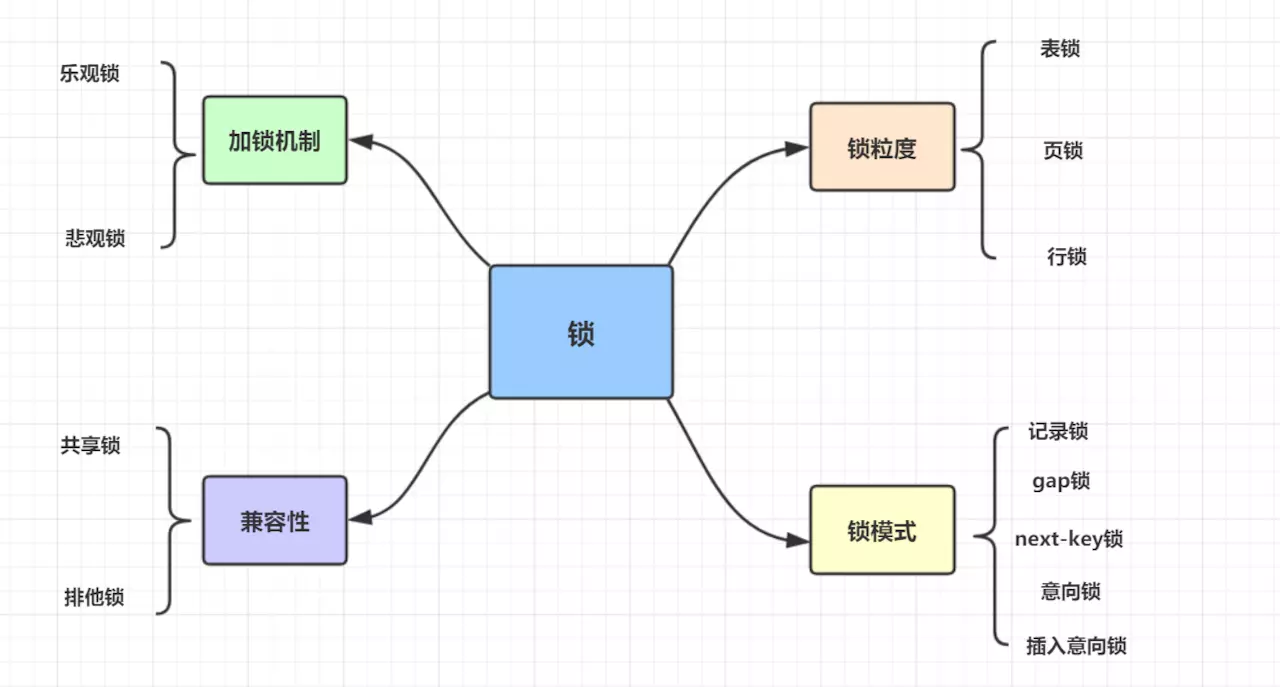
数据库中的锁
Mysql的读写分离
基于主从复制架构,主库写,从库读,主库自动将数据同步到从库
主从复制原理
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
主从同步延时
从库同步主库数据的过程是串行化的,主库上并行的操作,在从库上会串行执行,即会造成高并发场景下,从库的数据一定会比主库慢一些.
有两个机制主要解决此问题:
- 半同步复制
- 主要解决主库数据丢失问题。
- 主库写入 binlog 日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成。
- 并行复制
- 主要解决主从同步延时问题。
- 从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,完成库级别的并行。
本博客所有文章除特别声明外,大部分为学习心得,欢迎与博主联系讨论