GCN节点分类实验(一)
GCN实验
数据集介绍
实验数据集选用Cora数据集,该数据集由2708篇论文以及代表它们之间引用关系构成的5429条边组成。
数据集里论文按照主题大致分为七类:神经网络,强化学习,规划学习,概率方法,遗传算法,理论研究,案例相关。且每篇论文特征通过词袋模型得到,维度为1433,每一维表示一个词,1表示该词在文中出现过,0表示未出现过。
文本向量化表示–词袋模型
词袋模型使用一组词语序列来表示一段文本,这一组词语序列就是词袋模型,也可以叫词汇表。词汇表中每个词语之间的顺序是任意的,但是一旦词汇表确定后词语之间的前后顺序就不能变化了。由于词语之间的顺序任意,所以词袋模型忽略了文本的语法和语序要素。词袋模的One-Hot表示法、TF表示法、TF-IDF表示法的数值计算规则都没有考虑词语之间的共现关系。
TF表示法:词语序列中出现的词语其数值为词语在所在文本中的频次,词语序列中未出现的词语其数值为0。
TF-IDF表示法:词语序列中出现的词语其数值为词语在所在文本中的频次乘以词语的逆文档频率,词语序列中未出现的词语其数值为0。
逆文档频率:所有文档中出现频次的倒数
数据预处理
主要将数据下载后,规范化数据,最后将数据规范化为以下几个部分:
- X:节点特征,即维度为2708*1433。
- Y:节点对应标签,即上述7个类别。
- A:邻接矩阵,维度为2708*2708。
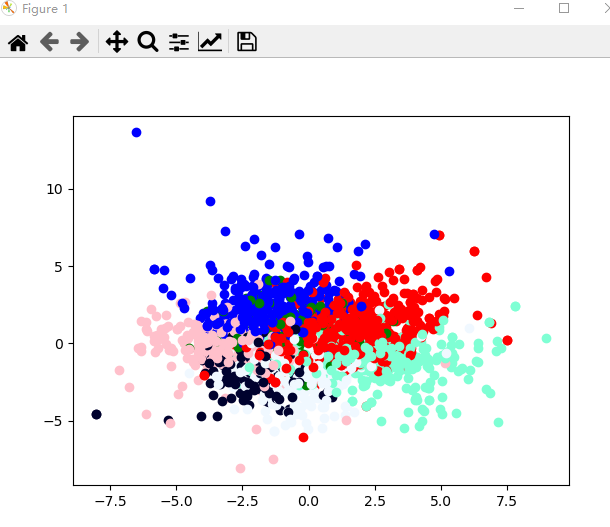
可视化结果
本博客所有文章除特别声明外,大部分为学习心得,欢迎与博主联系讨论