Redis学习笔记(二)
Redis
传统的关系型数据库如Mysql等已不能适用所有场景,如秒杀的库存扣减,APP的首页访问流量高峰等,这些情况都很容易把数据库打崩,所有Redis作为缓存中间件横空出世。
缓存穿透与布隆过滤器
判断不存在的数据没有必要让Mysql再次查询,Redis利用布隆过滤器挡下那些明显不会有结果的查询请求。
布隆过滤器
布隆过滤器可以用于检索一个元素是否再一个集合中,其优点是空间效率和查询时间都远超一般算法,但有一定的误识别率和删除困难。
布隆过滤器基本原理
布隆过滤器本质为bitmap位数组的扩展。例如有0-31范围的25个不重复数字,如何判断18在不在其中?
- 第一种做法是建立数字数组,使用int8单字节数组,需要8*32=256位,即32字节的空间。
- 第二种做法使用一个int32的变量,该变量4个字节,可用bit0表示数字0,bit1表示数字1,。。。依次类推。即知我们使用4字节空间就完成了方法一32字节的工作。
布隆过滤器两大组件
- 一定大小的BitAarry位阵列(具体大小与存储规模相关)
- N个可用的哈希函数(N的个数与存储规模,容忍误判率等有关)降低哈希冲突,尽量选用优秀的哈希函数。
两组件分工为,位阵列存储对应位的值是0/1的二进制向量,哈希函数将原始输入经过数字运算转换为一个数字值。
布隆过滤器与哈希冲突
哈希冲突虽然概率很低,但是在大规模数据场景下还是会出现,可尽量选用表现更优秀的哈希函数,或者多个哈希共同使用。
布隆过滤器的具体使用
假设三个哈希函数h1,h2,h3,有三个输入a,b,c已存在,分别通过三个哈希函数计算出对应整数后,对bitarray长度取模后将对应位置置1.
当布隆过滤器检索时,使用相同哈希函数进行计算,只要对应位置中,任何一个位置有0,则被检元素一定不存在,若对应位置都是1,则被检元素可能存在。
网上找图,如下所示:
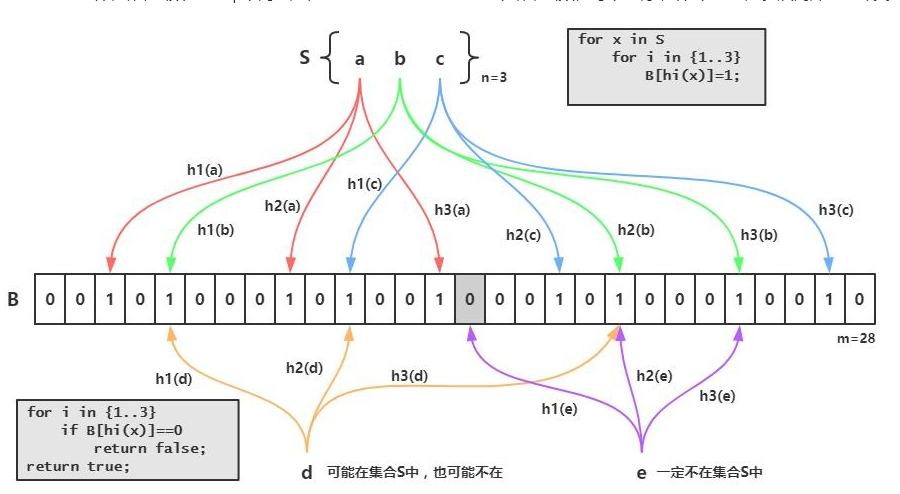
有0一定不存在,全1不一定存在
所以布隆过滤器存在一定的误判,主要因素包括:
- 哈希函数本身的冲突率
- bitarray位数组的大小
因为对位置重复赋值,所以一般不能从布隆过滤器删除元素
布隆过滤器的典型应用
- 缓存穿透过滤
- 检查单词拼写正确性
- 垃圾邮件过滤:如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
- 检查海量名单嫌疑人
- 搜索爬虫URL去重:爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
本博客所有文章除特别声明外,大部分为学习心得,欢迎与博主联系讨论