Redis学习笔记(一)
Redis
Redis是一个完全开源的高性能key-value数据库.
Redis的数据结构与应用场景
使用场景:缓存,共享session,消息队列系统,分布式锁
单线程Redis快的原因?
- 纯内存操作
- 单线程操作,避免了频繁上下文切换
- 合理高效的数据结构
- 采用非阻塞I/O多路复用机制
String字符串
字符串是Redis最基础的数据结构.其中键都是字符串类型,剩下几种数据结构都是在字符串类型基础上构建的.常用在缓存,计数,共享session,限速等方面.
Hash哈希
Redis中,哈希类型是指键值本身又是一个键值对结构的数据.可用来存放用户信息,实现诸如购物车等功能.
List列表(双向链表)
列表类型可用来存储多个有序的字符串,可做简单的消息队列功能.
Set集合
集合类型可用来保存多个的字符串元素,与列表不同的是,集合中不允许重复元素且元素无序,不能通过索引下标获取元素.可通过Set的交集,并集,差集等来计算重合元素.
Sorted Set有序集合
相对Set多了一个权重参数Score,集合中元素能按Score进行排列.常用来做排行榜,取Top N.
Redis的数据过期策略
Redis中数据过期策略采用定期删除与惰性删除策略
定期删除策略
Redis会启动一个定时器定时监视所有key,判断key的时效性,若过期即删除key。此方法能保证过期的key最终都能被删除。但本方法每次都要遍历内存中所有数据,非常消耗CPU资源。并且当Key过期后,定时器还未被唤起,这一段时间内的key仍然可用。
惰性删除策略
在获取到key时,判断key是否过期,若过期则删除。本方法缺点是:若某个key一直未被使用,则其将会一直在内存中,占用空间。
两者结合策略
定时删除策略不再扫描全部key。而是随机抽取部分key进行检查,从而降低对CPU的损耗。惰性删除策略弥补了可能未被检查到的key。若还是存在过期的key,既没有被定时器抽取,也没有被使用,则当内存不够时,使用内存淘汰机制进行淘汰。
移除最近最少使用的key/随机移除某个key
LRU(Least Recently Used) 最近最少使用
如何实现LRU
一般使用HashMap和双向链表实现LRU。使用HashMap存储key,而value指向双向链表实现的LRU的Node节点,如图:
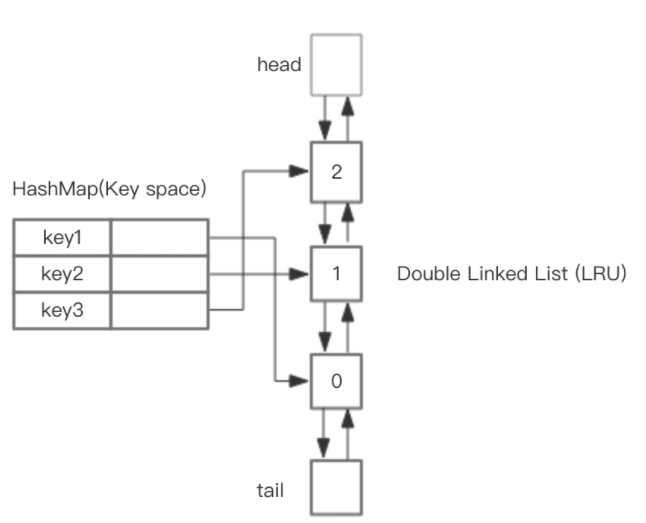
h表头,t表尾,预先设置LRU的容量。若存储满了,则O(1)时间淘汰掉双向链表的表尾。每次访问数据,都可通过O(1)效率把新节点增加到队头或把已存在点移动到队头。
Redis的LRU具体实现
Redis每次按key获取一个值时,都会更新value中的LRU字段为当前秒级别的时间戳。
第一版LRU为,随机从dict中取出五个key,淘汰一个LRU最小的。
在3.0时,改进一版算法,首先第一批随机挑选的key会放进一个pool中(默认大小16),pool中的key是按LRU字段大小顺序排列。接下来每次随机挑选的key的LRU必须小于pool的最小LRU才会继续放入,直至pool放满。放满后,若有新的key需要放入,则将pool中LRU最大的key取出。淘汰的时候,直接从pool中选取LRU最小的值进行淘汰即可。
Redis如何发现热点key
Redis主要有五种发现热点key的方法:
- 凭借经验预估:提前知道某个活动的开启,将该key作为热点key。
- 服务端收集:在操作redis前,加入计数代码进行数据统计。
- 抓包评估:Redis使用TCP协议与客户端通信,通信协议采用RESP,即自己写程序监听端口能进行拦截包分析。
- 在proxy层,对每个redis请求进行收集上报。(proxy–代理服务器)
- Redis自带命令查询:Redis4.0.4版本后,使用命令redis-cli-hotkeys能找出热点key
Redis缓存雪崩问题的解决
- 使用Redis高可用框架:使用 Redis 集群来保证 Redis 服务不会挂掉。
- 缓存时间不一致,给缓存的失效时间,加上一个随机值,避免集体失效。
- 限流降级策略:有一定的备案,比如个性推荐服务不可用了,换成热点数据推荐服务。
Redis缓存穿透问题的解决(待详细展开)
- 在接口做校验。
- 缓存击穿加锁/设置不过期
- 布隆过滤器拦截
Redis的几种集群模式
- 主从复制
- 哨兵模式
- cluster模式
本博客所有文章除特别声明外,大部分为学习心得,欢迎与博主联系讨论